用Ruby简书爬虫统计用户文章信息
思沃大讲堂培训,要求我们把自己学习的心得感悟输出在简书上,公司还会统计大家的文章,包括文章数量、评论量、被喜欢量等等。这么多人,人工统计起来自然很麻烦,当然程序员会把这么艰巨光荣繁琐的工作交给代码,于是他们就写了一个爬虫。适值极客人正在学习Ruby,所以就突发奇想写了一个Ruby爬虫统计简书用户的文章,带动自己的Ruby学习。 如果让我抓取一个网站的内容,我的第一想法可能会是抓取它的HTML,不过也会反过来问自己一句这个网站有没有Rss订阅源地址,RSS的订阅源的内容是xml,相比html更加简洁和高效,而且由于xml的结构稳定一点(html可能那天换一个css可能就会导致我的爬虫用不了啦),解析起来会更加方便一点。在考察完简书没有提供RSS后,我就决定选择html来暴力地抓取简书了。
分析简书网址
首页:**http://www.jianshu.com/**
用户主页:**http://www.jianshu.com/users/用户ID(暂估计这么说)**
我们可以获取用户的关注、粉丝、文章、字数、收获喜欢等信息
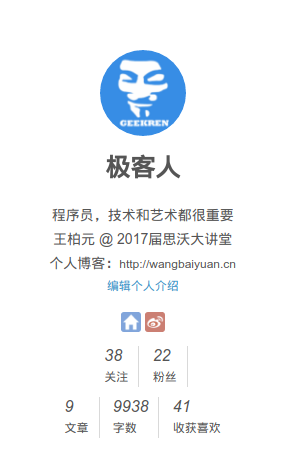
Paste_Image.png
用户最新文章**http://www.jianshu.com/users/用户ID(暂估计这么说)/latest_articles**
我们可以获取用户文章列表,以此统计用户文章的评论量、阅读量等等,通过遍历文章列表将评论量、阅读量相加即可获取评论总量、阅读总量
需要指出的是,由于文章列表页不能把用户的文章全部列出来,而是列出10条,用户在浏览器中滚动到文章列表底部会自动加载,是用js向后台请求数据然后在前端多次拼接出来,所以想一次性地抓一次就把用户的评论总量、阅读总量是不行的,用户列表页分页的。所以我采取分页抓取的方式,那么怎么知道用户文章一共有多少页呢?我们从用户主页中获取了用户的文章总数,所以除以10加1可以获取页数
- 用户列表页分页的,10条/页,其中第 m 页URL:
http://www.jianshu.com/users/用户ID(暂估计这么说)/latest_articles?page=m
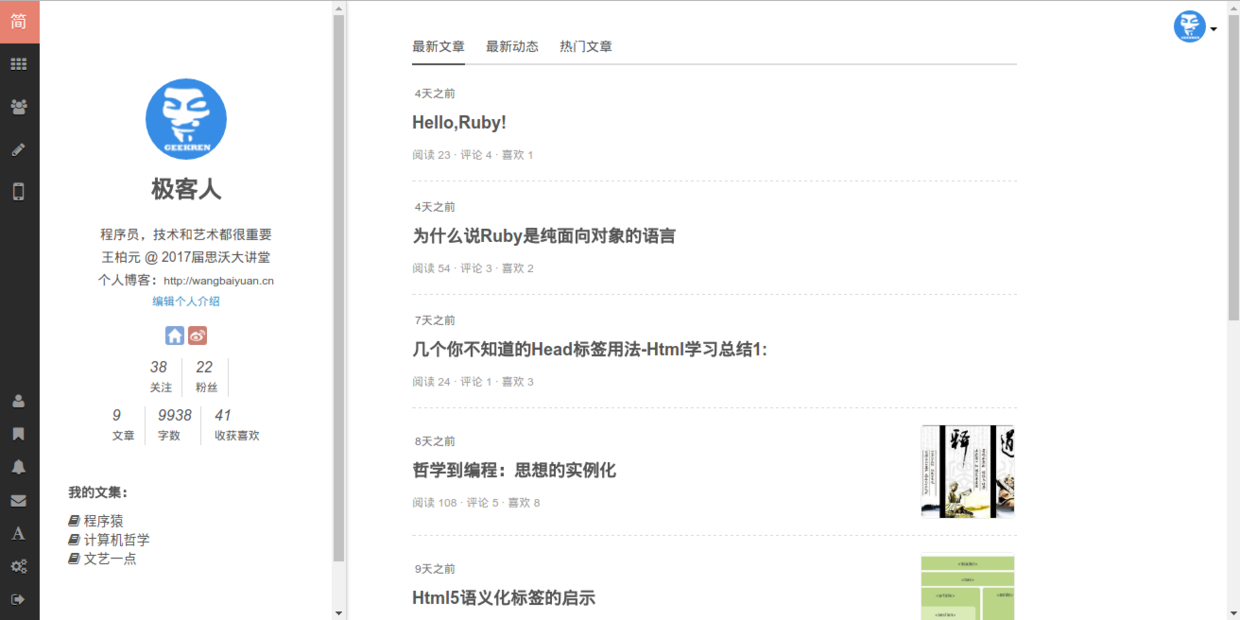
Paste_Image.png
抓取网页,获取html
Ruby提供的HTTP访问方法十分简洁高效,当然方法不止一种,对其他方法感兴趣的同学我自行Google,在此我贴出自己的代码:
h = Net::HTTP.new(“www.jianshu.com“, 80)
resp = h.get “/users/#{authorInfo.id}/latest_articles”
latest_articles_html = resp.body.to_s
顾问生义,我想不需要解释代码的意思了吧 根据上面介绍的简书网址规则,就可以通过上述代码抓取到相应网页的HTML
分析抓取内容的结构
获取完相应网页的HTML内容后要做的就是分析HTML的内容和结构。我们用眼睛很容易看出网页上的内容,但是爬虫看到的只有html源代码。下面我从抓取的HTML中提取了下列有用的代码:
- 用于提取用户的关注量、粉丝量、文章数、字数、收获喜欢数
- 用于提取用户文章评论总量、阅读总量
