保护日志中的用户隐私数据
2019年度“315”晚会人工智能拨打骚扰电话的情节,让大众了解到在信息时代,保护个人隐私的重要性。本篇文章分享了在日志记录中保护用户隐私数据的七个最佳实践。
与“中国人愿意用隐私交换便利性”的心态完全不同,欧美国家在个人隐私保护方面明显走得更早也更远一些。在2018年5月GDPR发布前后的一段时间里,保护个人隐私相关的需求被迅速提高了优先级,而像我这样一个开发国际化产品的普通程序员,日常工作也因此受到影响,我们放下手中的业务需求卡(Story),转而去做GDPR相关的安全需求。 一般在医疗保健或金融行业中,限制访问客户的敏感数据有着非常严格的规定,尤其欧洲GDPR颁布之后,公司泄露个人数据的后果也非常严重。在个人隐私保护方面,国内目前在法律和意识方面处于滞后的状态,但是许多人或多或少都感受到个人信息泄露给自己带来的麻烦,比如骚扰电话的增多就是最明显的例证。比较乐观的是网络安全法的发布,以及网民意识的觉醒,表明我们的个人信息保护正在路上。 对于一些面向欧美的项目,从公司最高层面,自上而下,我们采取了一系列相关动作,比如梳理我们基础设施架构图、数据流图、API数据字段分析等,其中包括保护日志中的个人信息。
安全问题的特殊性
个人隐私安全和其它安全问题一样,是一个永远做不完的需求。你不能说你的网站是绝对安全的,只能说“我检查了所有目前已发现的安全漏洞列表(Checklist),并且采取了相应的防御措施,做到尽量安全”,或者说我们采取了一些很好的安全实践,比如采取了动态密码、在nginx上安装了防攻击防SQL注入插件等等。 现在的Web系统一般都配备了日志系统用于记录访问请求、分析线上事故等,比如开源的有ELK,SaaS的有DataDog、Sumo Logic 等。 在日志记录过程记录下一些用户隐私信息往往是不可避免的。诚然,开发者的个人隐私保护意识是很重要的,但有时并不一定是开发者的主动想偷窥用户信息。比如这里举一个很常见的情况,有些程序异常如果没有合理捕获,往往会输出调用堆栈,这些调用堆栈里面某些方法的参数可能就包含有个人隐私信息; 虽说没有一种一劳永逸的方式来避免个人信息出现在日志中,但我们可以通过下面的实践来尽量规避,并将这些内建在自己平时的开发工作中。下面的实践,一些涉及到了代码层面的技术实践、团队流程的优化,还有的是测试、运维上的一些措施。
首先:确定什么是隐私数据
在我们深入讨论怎样避免个人隐私数据出现在日志之前,我们来界定什么是_隐私数据_:
- 个人可标识数据(PII):如社会安全号码,数据组合(如名字+出生日期或姓氏+邮政编码)或用户生成的数据(如电子邮件或用户名,如blog@mail.baiyuan.wang),手机号。
- 健康信息
- 财务数据(如信用卡号)
- 密码
- IP地址:IP地址也有可能是个人隐私数据,尤其是与个人可标识数据与其有某种绑定关系。(而2019年的3.15晚会介绍一种将MAC也变成了PII的方式)
个人隐私信息不一而足,其界定工作可能需要与熟悉GDPR的安全专家合作来完成,根据实际情况彻查应用内的数据,来确定什么是敏感的。
一、解耦隐私字段
处理隐私数据时,应尽量减少系统使用这些数据的频率。比如在数据库表设计时,使用电子邮件地址Email,或者极端一点的例子,使用身份证号码(下称PID)来作为“用户”表的主键。这意味系统在访问用户数据时,都需要使用Email或者PID来建立关联关系,这样做可能会非常省事,而且系统也是完全可以工作的,但是这极大地提高了敏感字段的曝光率,出现的地方越多,意味着被日志记录下来的几率越大。 所以更好的方法是解耦出隐私数据,只在在必要时才使用它。一种常见的解决方案是将随机生成的字符串作为用户表的ID,同时建立一个“1对1”的数据库表来存储用户ID与用户数据库表主键的关系。例如:
PID | 外键
————————-
42-12xxxx-345 |5a2_cXKrt32DcWOJpJlyhr7FhTcLPfvlEAb1eA2Hza
在用户表以外的所有数据库表,都应该使用这个随机ID进行查询,这种随机ID即使被暴露也不会泄露任何个人数据。
二、避免在URL中出现个人隐私信息
比如你有一个RESTful API,通过Email来查找用户信息,则可能很容易拥有这样一个Endpoint,如:**/user/
三、对象打印重写toString方法
为了定位问题或者debug的方便,开发经常会在日志中添加一个调试信息。因为追求方便的缘故,可能写出这样的代码(将User直接打印,而不是user.username):
logger.info(“为用户$ {user}更新电子邮件);
一些程序语言,比如Java、Javascript,如果将一个对象直接进行打印,它其实是打印 toString方法返回的字符串,这样我们可以重写对象的toString方法来避免打印对象时出现的个人信息泄漏问题。
class UserAccount {
id:string
username:string
passwordHash:string
firstName:string
lastName:string
…
public toString(){
return “UserAccount (${this.id})”;
}
如果开发人员实在“作死”的话,比如直接打印对象的字段就没有办法了,例如: logger.info("The user's details are: ${user.firstName} ${user.lastName}");
四、结构化日志输出时屏蔽隐私字段
为了日志方便查看,我们常常将日志以Json字符串的形式上传到日志服务器,这样我们查看日志可以清晰看到键值对结构。 我们可以在应用的日志输出中,遍历所有键值对信息,如果“键”存在firstName这样的字段,或者“值”中能匹配到Email,那么将对应的值替换成“
Blacklist = [“firstName”, “lastName”]
EmailRegex = r”.+@.+”;
class Logger {
log(details: Map<string,string>) {
const cleanedDetails = details.map( (key, value) => {
if (Blacklist.contains(key) || EmailRegex.match(value)) {
return (key, “
}
return (key, value);
}
console.log(JSON.stringify(cleanedDetails));
}
}
五、将日志代码审查纳入Code Review
Code Review是开发过程中可以保证代码质量的部分,比如在Code Review中常常会被别人指出程序漏洞、健壮性问题、改进建议等等。将日志代码的检查作为Code Review中各个成员关注的一部分。这个方面不是技术层面,而是团队Code Review流程上的改善。 如果使用的是Pull Request Template 来进行合并代码,则可能需要在模板中设置一个复选框,提示reviewer进行检查。
六、个人信息泄露测试纳入QA和自动化测试
虽说目前大部分公司的实践,并没有把个人隐私泄露测试纳入测试或者QA人员的工作范围,但是这部分的工作不仅需要测试来做,而且甚至可以自动化。 比如一个用户注册的场景,测试人员可以模仿用户在Web前端表单填写姓名、Email后,检查服务器日志中是否含有这些信息。而这部分工作可以使用Selenium、Cypress等端到端测试工具,然后调用日志服务器的API来搜索这些信息是否存在,来实现自动化。 自动化的个人隐私泄露测试也可以将其纳入到CI/CD持续集成流水线中。
七、在日志收集器上传前“打码”隐私信息
在我们的项目中,一般存在两种日志收集方式
- 通过日志中心提供的日志收集进程(代理程序、Agent),将机器实例的标准输出或者日志文件内容,推送到日志服务器
- 通过AWS Lambda无服务器代码转发日志到日志中心
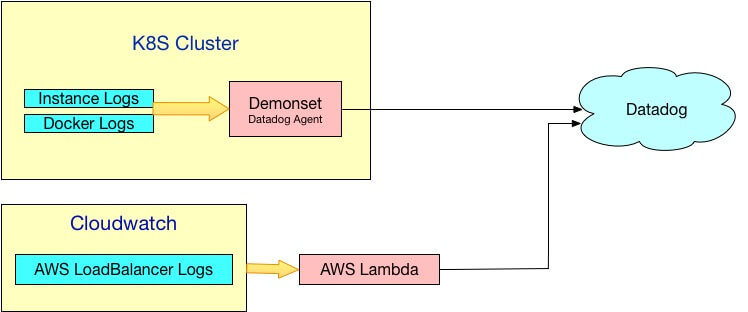 日志收集工具是日志到达日志中心的必经之地,在这个关口做好信息屏蔽,就可以对来自所有服务(多个微服务的情况下)的日志做集中式的处理。Datadog Agent直接提供了屏蔽隐私数据的配置,而AWS Lambda的代码则是我们可控的,可以自己实现代码层面的正则替换。
日志收集工具是日志到达日志中心的必经之地,在这个关口做好信息屏蔽,就可以对来自所有服务(多个微服务的情况下)的日志做集中式的处理。Datadog Agent直接提供了屏蔽隐私数据的配置,而AWS Lambda的代码则是我们可控的,可以自己实现代码层面的正则替换。
八、日志系统中配置个人隐私信息的监控告警
即使有了上面的实践,我们依旧不能保证个人隐私绝对不会出现在日志中,一方面我们可以在平时Debug、查看应用日志时有意识地检查有没有含有隐私信息,另一方面我们还是可以通过一些技术手段将这一检测工作自动化,并通过告警系统通知到团队成员进行处理。  在监控系统配置Email告警 这已经在笔者所在的团队中得到实践。我们使用Datadog作为日志、监控系统,成功实现在日志中出现Email信息时,Datadog能自动发送邮件通知。但是需要指出的一点是,因为Email可以很好地通过正则表达式进行匹配,同时被很多日志系统所支持。但是对于姓名这些信息,可能只能交给人工智能了。
在监控系统配置Email告警 这已经在笔者所在的团队中得到实践。我们使用Datadog作为日志、监控系统,成功实现在日志中出现Email信息时,Datadog能自动发送邮件通知。但是需要指出的一点是,因为Email可以很好地通过正则表达式进行匹配,同时被很多日志系统所支持。但是对于姓名这些信息,可能只能交给人工智能了。
总结
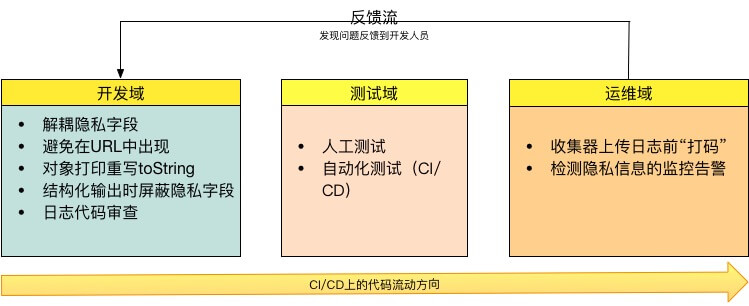 PII Protection 从上面的阐述中可以看到,个人隐私信息的保护,已经不是请一个安全专家就能简单解决的问题,也不是单独的某个角色的工作,而是需要整个团队各个角色的通力合作。这就是DevSecOps理念。
PII Protection 从上面的阐述中可以看到,个人隐私信息的保护,已经不是请一个安全专家就能简单解决的问题,也不是单独的某个角色的工作,而是需要整个团队各个角色的通力合作。这就是DevSecOps理念。
其实是像表达在这种情况下,正则匹配就解决不了这个问题,估计要丢给人工智能吧。具体怎么做我也不了解,看见有人写过这样的论文,我目前还没看到落地的产品。
你好!我最近想利用机器学习对日志中的用户隐私进行识别和处理,您文章中有提到姓名之类的识别要交给人工智能请问是什么意思,关于日志中的隐私识别请问是否有一些是不仅仅利用正则匹配而是利用机器学习进行识别分类的地方呢 谢谢!
你说的很对,因为我现在在做DevOps,所以着重讲这一块,一方面从日志收集方面,一方面是作为owner推动PII保护的工作在team中的发生。安全的确需要团队各个Role都要有一定的意识。
TW开始注重这方面了?难得 很全面且落地的用户隐私防范,不错 另外,还可以结合前端,请求发送之前对隐私数据加密,后台解密,存储时再加密,特别用于密码,这些严格来说还得体现在业务需求上,但是除了开发基本不可能意识到吧